
There are many ways to increase Google search traffic, but here’s an example of one site where we doubled (and more) daily traffic just by fixing some fundamental technical problems.
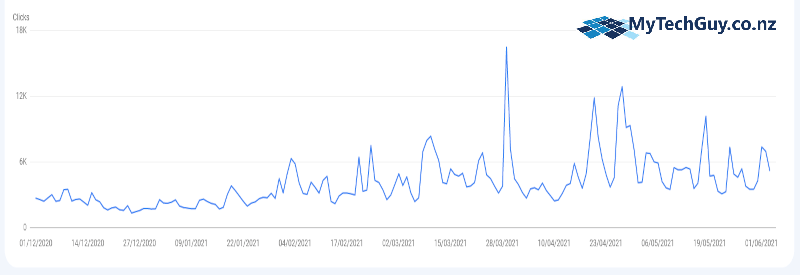
It’s a little hard to see on the graph but the daily traffic was around 2-3,000 clicks per day, and after applying our SEO services the website traffic now averages at 5-6,000 clicks per day with peaks hitting 10-12,000+. This is just search traffic as reported by Google Search Console (what is Google Search Console?).
Why Did Google Traffic Increase So Much?
Google is a search engine, and therefore just a machine. It’s a very clever machine designed by some of the world’s best technical brains, but it is still a machine.
It’s job is to give you a list of the best possible web pages for the search term you type in. Determining what is ‘best’ however depends on (quite literally) hundreds of different things. All of these ‘signals’ combined together determine what page comes out at No.1 and gets most of the clicks (and what page comes out at No.50 and never gets seen).
So you always have to put your best foot forward to help Google decide if your page is a better result to show than your competitors pages.
That’s a big part of what SEO (or Search Engine Optimisation) is all about. Getting all the technical stuff in place to help Google understand your website properly and why your page is better than other pages. You need to feed the machine what it likes to eat.
By fixing the things Google didn’t like about this website, and improving things to help Google better understand the site, they naturally determined it should rank better and get more clicks. We fed them more of what they wanted to eat.
If you need an SEO consultant to work with on your own website, check out our SEO services or get in touch to see if your site is suitable for our services.
So How Did We Achieve This Google Search Traffic Increase?
This particular site had really good written content, so we didn’t change any of that content. All of the changes we made were technical fixes. I’ll break these down into general areas:-
Archive Pages – Categories, Tags & More
This site was a WordPress based site, but the same principle applies to other types of website. WordPress is designed ‘out of the box’ to organise your content by categories and tags (i.e. taxonomies). It’s a useful system but often incorrectly used.
WordPress automatically creates pages for each category and tag summarising the content in those taxonomies. By default, to avoid really long pages, it splits these ‘archive pages’ into 10 items per page. It’s much more user friendly to have a page of 10 items, then hit ‘next’ to see more.
Now consider what happens when you have many thousands of articles, and dozens of categories and dozens of tags. Each article can have multiple categories and multiple tags. This very quickly creates thousands of extra pages on your site which (by default) you are telling Google are important.
What you need to consider is whether these pages are really adding anything useful to your site. Or are there simply hundreds of near identical pages?
Things to look out for in particular are:-
- A site should never have both a tag and a category that are the same
- Don’t create tags that are too granular (i.e. if there will only ever be 1 or 2 posts with that tag, it’s not a useful tag)
- Check tags for typos – mispelled tags look bad anyway but also ‘weaken’ the correct tag archive
- Avoid using 2 very similar tags if 1 tag covers both
- If you find you are tagging (or categorising) nearly every post with the same thing, then that taxonomy is too general and not useful
Fixing these problems will improve what Google actually add to their index, and affect their overall perception of the quality of your site.
Can Google Get There?
If Google can’t get to a page it can’t know what it’s about. That’s fairly obvious, although still a problem with many sites.
There can however be a deeper ‘hidden’ problem here. Google may be finding pages by other means (such as an XML sitemap), but if your website doesn’t actually link to those pages in a way that Google can see then it suggests to Google that you don’t think those pages are important (so they shouldn’t think so either, right?).
We refer to this in the ‘SEO world’ as ‘crawlability’ – i.e. can Google crawl through your website just following links and still discover all of your pages.
One thing in particular to watch out for is the ‘infinite scroll’ (or infinite load) that is a popular feature on many websites. It’s that feature where more content loads in as you reach the bottom of a page – it may be more articles on a category page or another article after you’ve read the current article.
The danger here is that Google doesn’t do this – when they crawl your website they behave a lot like a normal person, but this is one area where they can’t. Not because it’s technically impossible, but because it’s impractical (how long should they scroll for?) and potentially harmful (how long should they hammer your web server by continuing to scroll all the pages?). It’s also not useful in determining what that particular page is really about – it’s really about what is in the page to start with. The problem here is if scrolling the page is the only way to get to ‘deeper’ content. Google needs links to follow.
Pages That Don’t Really Exist
Sometimes Google can index pages that have little or no real content on them. They’re not real pages, these ‘ghost pages’ only exist because of a technical problem elsewhere. This can happen for various reasons – from poorly designed plugins to broken theme code.
There’s no easy answer to finding pages like this, experience helps and digging through the indexing reports in Google Search Console.
If you find pages like this ideally you work out why they are happening and fix the source of the problem so they no longer exist at all. If that’s not possible then you find a way to ‘noindex’ them so Google is clear that these are not real pages and should be ignored.
Hidden Code (Open Graph and Schema)
Modern websites have a lot of hidden data (or meta data). It’s used for for things like determining how social shares appear – if you’ve ever shared something on Facebook and no image appeared, this is why, it’s lacking some meta data in the form of Open Graph tags.
This kind of data is also used by Google itself. There are various types of hidden data called ‘schema’ that detail in a computer readable all sorts of things about who your business is and what you do. If you’ve ever searched Google for a recipe and got ‘rich results’ that show all sorts of extra things about that recipe even before you click – that’s schema.
If you don’t have schema or open graph set up, your site could be missing out greatly.
Test Pages, Miscellaneous User Pages & More
Some pages on your site are just not ‘content’ pages. They are still valid pages that are useful to the users of your site, but they’re just not something Google needs to know about.
This covers everything from login pages to demo or test pages, staff only pages to pages that confirm some action such as an email optin. None of these pages have any good reason to be indexed by Google. If they are no longer needed, delete them. Otherwise ‘noindex’ them.
We found one page in particular here that had been accidentally set up with the wrong page template. It was supposed to be a simple content page – instead it ended up creating thousands of entirely duplicate pages, 97 of which Google had indexed! Fixing it was simple, change the page template to the correct one, it’s finding and recognising major problems like this that takes significant SEO expertise.
Broken Links – Internal & External
Most websites of any age will have some broken outdated links somewhere on them. It’s a natural part of the web – pages and websites come and go, websites change the software they are built on which can change the URL of pages, it happens.
Google understands this and will of course make allowances for it. Look at it from their point of view though – they are trying to deliver a quality result to someone searching for information. If a particular website has a vast amount of links that don’t work, it says quite a lot about the quality of that site. It means nobody bothers to check or fix things.
Even worse if lots of those links are to their own pages.
There are various tools to scan and find broken links – doing a good job of fixing them however is quite labour intensive. Links should be replaced with the correct updated link (or a better replacement) where possible. It’s good for your site visitors and is therefore also good for Google.
Wrapping Up
Increasing Google search traffic with SEO can take various forms. In this case we were able to double search engine traffic alone just by fixing technical issues. The site owners weren’t aware of any of these issues because they didn’t show up as errors.
The real skill of an SEO consultant comes in knowing how to assess a site and the type of problems that can give Google a reason to consider your site to be less worthy of that No.1 position in the search results. Then know how to fix it.